Les parties précédentes de ce programme d’apprentissage ont défini les termes clés liés à l’identité (voir Qu’est-ce que l’identité numérique – Partie 1), et décrit le cycle de vie de l’identité numérique (voir Qu’est-ce que l’identité numérique – Partie 2). Intéressons-nous maintenant à trois autres sujets :
- Les lois canadiennes entourant les renseignements personnels.
- Les modèles d’identité numérique
- Le principe de l’identité auto-souveraine
Identité numérique et protection de la vie privée
Les renseignements contenus dans les transactions d’identité numérique sont généralement des renseignements personnels. Par conséquent, les mesures de protection de la vie privée visant à protéger ces renseignements sont la pierre angulaire de l’identité numérique au Canada.
Lois sur la protection des renseignements personnels et la LPRPDE
Au Canada, le gouvernement fédéral et chaque province et territoire ont mis en place des lois sur la protection des renseignements personnels qui régissent la façon dont les gouvernements recueillent, utilisent et communiquent les renseignements personnels. Le gouvernement du Canada, la Colombie-Britannique, le Québec et l’Alberta ont également mis en place des lois sur la protection de la vie privée qui régissent la façon dont les organisations du secteur privé recueillent, utilisent et communiquent les renseignements personnels. Pour le gouvernement fédéral, ces lois sont la Loi sur la protection des renseignements personnels et la Loi sur la protection des renseignements personnels et les documents électroniques (LPRPDE).
La Loi sur la protection des renseignements personnels porte sur la façon dont le gouvernement fédéral doit traiter les renseignements personnels, et sur les droits d’une personne à accéder à ses renseignements personnels et à les corriger.
La LPRPDE établit les obligations légales des organisations du secteur privé engagées dans des activités à but lucratif.
La LPRPDE énonce 10 principes relatifs à l’équité dans le traitement de l’information. Ceux-ci servent de lignes directrices pour les standards de protection des renseignements personnels :
- Responsabilité
- Détermination des fins de la collecte des renseignements
- Consentement
- Limitation de la collecte
- Limitation de l’utilisation, de la communication et de la conservation
- Exactitude
- Mesures de sécurité
- Transparence
- Accès aux renseignements personnels
- Possibilité de porter plainte à l’égard du non-respect des principes
Ces principes dictent qu’une personne devrait :
- savoir ce qui est demandé et pourquoi;
- être invitée à consentir à la transmission et au partage de renseignements personnels;
- savoir comment les renseignements personnels sont utilisés et partagés;
- être assurée de la protection des renseignements personnels; et
- avoir l’assurance que seuls les renseignements nécessaires sont demandés et partagés.
Les mesures de sécurité prévues par ces différents textes législatifs relatifs à la protection de la vie privée s’appliquent à tous les renseignements personnels. Dans le contexte de l’identité numérique, ces renseignements personnels sont généralement un attribut du justificatif, comme le nom, le numéro de téléphone, la date de naissance, etc.
La mesure dans laquelle une personne contrôle ses propres renseignements personnels, lorsqu’ils sont associés à un justificatif, dépend de la manière dont un écosystème d’identité numérique particulier a été conçu. Il existe de nombreux modèles dans le domaine de l’identité numérique. Chaque modèle a ses avantages et ses inconvénients. Examinons quelques-uns des modèles les plus courants pour l’identité numérique.
Modèles d’identité numérique
Identité et justificatifs centralisés – dans ce modèle, un compte est créé, contrôlé et détenu par l’organisation avec laquelle une personne effectue une transaction. Il peut s’agir, par exemple, de créer un compte en ligne pour acheter des produits dans une boutique en ligne, de s’inscrire auprès de sa province pour accéder à des informations de santé ou de s’inscrire à une banque en ligne.
Dans chaque cas, l’organisation détermine ce qu’elle doit savoir sur vous pour vous délivrer un justificatif (par exemple, un code d’utilisateur et un mot de passe) permettant d’accéder à son site. Dans le cas d’un achat sur une boutique en ligne, il se peut qu’elle veuille simplement savoir que vous avez une adresse courriel et une carte de crédit valides. Qui vous êtes n’a probablement pas d’importance. Dans le cas de l’accès à des informations médicales ou bancaires, l’organisation aura besoin de beaucoup plus de certitude quant à votre identité pour s’assurer que les bons renseignements personnels sont transmis à la bonne personne. Vous devrez peut-être vous rendre dans un bureau physique lors de la création de votre compte ou suivre d’autres types d’étapes pour l’inscription. Cependant, quel que soit le degré de certitude dont l’organisation a besoin, ce qui rend ce modèle centralisé est que l’organisation contrôle ultimement les informations que vous fournissez pour créer le compte.
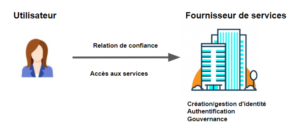
Les modèles centralisés étaient les plus pratiques à mettre en place lorsque la technologie et les standards étaient moins avancés. Cependant, plusieurs problèmes sont apparus :
- L’utilisateur, par nécessité, renonce au contrôle de ses renseignements personnels;
- Une seule fuite peut compromettre une grande quantité de renseignements personnels, car ils sont tous stockés (souvent au même endroit) par l’organisation;
- Les multiples points de défaillance uniques rendent le système dans son ensemble moins fiable; et
- En tant que système fermé, il ne se prête pas bien à une utilisation au-delà du fournisseur de services émetteur.
Identité fédérée – ce modèle permet l’authentification unique, ce qui ouvre la possibilité d’utiliser une identité numérique (par exemple, votre identifiant bancaire ou votre identifiant pour un média social) pour accéder à plusieurs domaines. Dans ce modèle, nous voyons l’introduction d’un fournisseur d’identité. Une identité (ou un compte d’utilisateur) établie et/ou gérée par une organisation est utilisée pour accéder aux services d’une autre. Un exemple est l’utilisation d’un partenaire de connexion pour se connecter à votre compte de l’Agence du revenu du Canada.
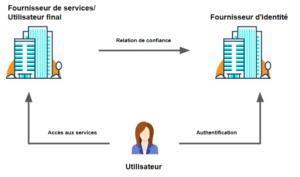
Les modèles d’identité fédérée présentent un grand nombre des mêmes risques que les modèles centralisés. Cela inclut les points de défaillance uniques, les dangers associés aux répertoires centralisés et l’abandon du contrôle des données des utilisateurs finaux. Il y a également de nouvelles complexités introduites:
- L’interopérabilité et les intégrations avec d’autres systèmes deviennent coûteuses et difficiles à maintenir; et
- L’exigence d’intégrations «point à point» entre les fournisseurs de services et les vérificateurs entrave considérablement l’évolutivité.
Toutefois, ce modèle présente certains avantages :
- La possibilité d’accéder à plusieurs services en utilisant une seule identité numérique;
- Ces systèmes sont basés sur des standards avec des méthodes cohérentes pour l’échange d’informations; et
- Bien que le risque d’attaque d’un répertoire centralisé d’informations sur l’identité numérique existe toujours, les informations d’identité sont gérées par des organisations qui ont pris la décision délibérée de gérer l’identité numérique, ce qui signifie qu’elles sont plus susceptibles d’avoir des niveaux plus élevés de sécurité et de gouvernance en place pour protéger ces informations.
Identité décentralisée – ce modèle est centré sur l’utilisateur. Dans ce modèle, une personne (l’utilisateur) crée son identité numérique par le biais d’un processus d’inscription au cours duquel elle prouve, hors de tout doute raisonnable, qu’elle est bien celle qu’elle prétend être. Ce processus pourrait être similaire, par exemple, à celui que vous suivez pour obtenir un permis de conduire. Une fois le processus d’inscription terminé, l’utilisateur contrôle la manière dont les informations sont partagées et avec qui. Pour reprendre l’exemple du permis de conduire, l’émetteur (dans ce cas, un gouvernement) sait qu’un permis de conduire vous a été délivré, mais une fois qu’il vous a été délivré, vous avez le contrôle. Vous choisissez quand vous montrez votre permis de conduire et à qui. L’émetteur ne sait pas quand et où vous l’avez partagé.
Ce processus de délivrance et de partage est hébergé sur un réseau. Il s’appuie souvent sur la technologie de la chaîne de blocs en utilisant des registres distribués et des techniques de cryptographie. Par conséquent, aucune base de données centralisée n’est nécessaire.
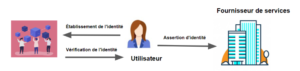
La technologie des registres distribués utilisée dans les réseaux d’identité décentralisés permet de faire confiance au réseau sans le contrôle d’une autorité centrale. Cela signifie que :
- Il n’y a pas d’administrateur central ni de stockage centralisé des données;
- Le réseau d’identité est formé par des pairs qui ont les mêmes autorisations et qui transigent librement entre eux;
- Les transactions sont effectuées par un mécanisme de consensus (les ententes entre les parties sur le statut du registre);
- La cryptographie à clé publique permet un niveau de sécurité approprié; et
- L’intégrité des données est maintenue; donc
- Les utilisateurs sont en possession et ont le contrôle de leurs données; et
- Les données sont sécurisées.
Dans le modèle centralisé, l’organisation qui fournit le service est la seule autorité (dans notre exemple centralisé, il pourrait s’agir d’une banque). Elle définit les règles, crée les identités, fixe les conditions de la gestion d’une identité (dans les limites des lois applicables). Dans les modèles fédérés ou décentralisés, différentes entités seront responsables des activités. Un justificatif peut être créé par une organisation. L’authentification peut se faire par le biais d’un autre système de sécurité. La validation peut être effectuée par un tiers avant d’être finalement vérifiée par une autre entité, avec le consentement de l’utilisateur. Une compréhension commune de la gouvernance et des standards opérationnels impliqués est cruciale.
L’identité auto-souveraine
Souvent, les termes identité auto-souveraine et identité décentralisée sont utilisés comme synonymes. Il existe plusieurs définitions, avec quelques variations sur la gouvernance et la technologie. Nous définissons l’identité auto-souveraine comme une méthode d’identité décentralisée où l’utilisateur a le contrôle absolu du partage et de la divulgation. Par exemple, prenons l’exemple ci-dessus où un permis de conduire est présenté dans un bar. Dans ce cas, le portier n’a besoin que de confirmer que vous avez l’âge légal pour boire. Il n’a pas besoin de connaître les autres informations figurant sur le justificatif, telles que votre adresse, la couleur de vos yeux, votre poids ou même votre date de naissance exacte. Il suffit de prouver que votre âge est égal ou supérieur au seuil minimal. Dans un modèle décentralisé, vous pouvez choisir avec qui vous partagez votre justificatif, mais vous devez quand même partager le justificatif complet. Dans un modèle d’identité auto-souveraine, vous pouvez préciser davantage ce que vous partagez en choisissant les attributs que vous partagez (par exemple, âge, date de naissance, adresse, etc.). C’est ce qu’on appelle la divulgation sélective. Nous reviendrons sur ce sujet dans des publications à venir.
Comme tout modèle, la mise en œuvre d’une identité auto-souveraine peut varier, mais il existe plusieurs caractéristiques communes fondamentales. Les principes de l’identité auto-souveraine offrent plusieurs avantages qui ne sont pas possibles dans les modèles traditionnels :
- Partage uniquement de ce qui est absolument nécessaire;
- Une meilleure protection de l’intégrité des données;
- Une réduction significative de la dépendance envers des technologies particulières;
- Les émetteurs n’ont pas besoin de faire l’intégration avec les vérificateurs;
- Les émetteurs ne savent pas quand leurs justificatifs sont utilisés (les transactions restent entre l’utilisateur et le vérificateur);
- Aucune dépendance envers des autorités centralisées ou tierces pour l’authentification; et
- Une réduction significative de la charge de gestion des authentifiants.
Un aperçu de l’apprentissage à venir
Nous avons abordé l’une des questions les plus importantes concernant l’adoption de l’identité numérique : la vie privée et la protection des renseignements personnels. Nous avons également identifié certaines des mesures clés en place pour contribuer à atténuer les préoccupations en matière de protection de la vie privée, telles que les lois et les modèles de mise en œuvre.
Dans les prochaines parties de ce programme d’apprentissage, nous examinerons de plus près d’autres composants de la structure d’un écosystème d’identité numérique. Nous examinerons d’autres facteurs affectant l’adoption de l’identité numérique et les moyens d’y remédier. Les standards et les cadres associés à la gestion décentralisée de l’identité évoluent rapidement. Des standards largement adoptés sont importants pour garantir que tous les acteurs dans le domaine de l’identité numérique puissent travailler ensemble. Les mécanismes d’évaluation de la conformité à ces standards sont tout aussi importants.
Nous serions ravis de vous entendre et de répondre à vos questions les plus fréquentes! Contactez IDLab!
